
A primera vista hay dos grandes diferencias técnicas entre OpenERP y Openbravo, la primera es la arquitectura. Mientras openbravo está desarrollado en Java JEE y se ejecuta sobre Tomcat (es el recomendado por Openbravo) y por tanto su arquitectura se podría resumir en este gráfico.
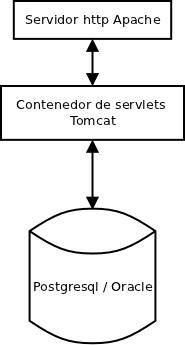
OpenERP tiene una arquitectura en la que separa claramente las diferentes capas, por una lado tiene el servidor que maneja la lógica, al igual que Openbravo tiene la base de datos, y en un tercer nivel tenemos las diferentes vistas. En este caso se ha utilizado Python para desarrollar las diferentes capas.
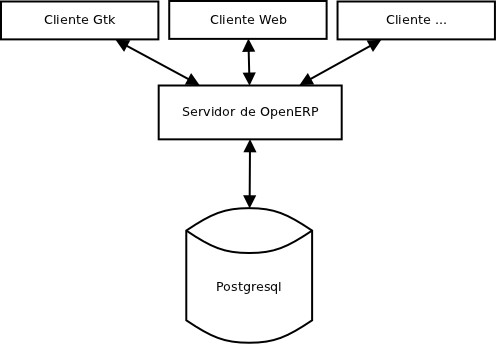
Las desventaja que tiene Openbravo en cuanto a arquitectura es que su interfaz (vista) está centrada en el web. La única forma de conseguir una interfaz diferente a una básada en tecnología web es utilizandos servicios web, este es el caso por ejemplo del TPV (Terminal Punto de Venta), es la misma tecnología que podríamos utilizar para integrar cualquier otro sistema externo. En el caso de OpenERP el acceso al servidor está estandarizado, esto significa que podemos desarrollar el cliente que queramos pero todos accederán de forma estándar al servidor.
La segunda gran diferencia es el hecho de que Openbravo utilice mucho código en base de datos en forma de funciones (procedimentos almacenados pl /sql), triggers y restricciones. En el patrón MVC (Modelo Vista Controlador) de Openbravo se desplaza gran parte de la lógica (Controlador) a la capa de de acceso a datos (Modelo), esto genera varios problemas.
Por una parte se dispersa la lógica entre el controlador (código java en el contenedor de servlets Tomcat) y el Modelo (código pl /sql, trigger y restricciones en la base de datos). Otro problema es que la independencia de base de datos queda casi descartada, además el matenimiento del código de base de datos se complica hasta tal punto que migrar de una versión del gestor de base de datos a la siguiente puede resultar un problema. Por ejemplo, Openbravo 2.50 no soporta oficialmente postgresql 9.1, que es la última versión.
Openbravo intenta solventar parcialmente este inconveniente con DBSorucesmanagement, que permite estandarizar de forma más o menos elegante el código en base de datos y exportarlo a xml. Hasta el momento soportan Postgresql y Oracle y aunque no es perfecto, no suelen haber muchos problemas graves, y los que hay suelen solucionarse sin excesivas complicaciones, eso si, hay que generar el código pensando en esta compatibilidad.
En OpenERP no existe código en base de datos, por lo que la independencia de base de datos es mucho más fácil de conseguir. Además en OpenERP actualizar de una versión de la base de datos a la siguiente es casi inmediato. Pero entonces ¿dónde está el código?, pues es sencilo, la lógica está toda en la capa de controlador.
Ya iremos desgranando más diferencias en otros apuntes.
Nota:
Estoy ofreciendo unos mini cursos de desarrollo en OpenERP por 200€.
Cheli
Hola gracias por el árticulo, me puedes ayudar a instalar openerp en ubuntu 12.04, gracias
Pues con la información que me has dado no se en que te puedo ayudar.
El código en base de datos en forma de funciones, procedimentos almacenados pl/sql, triggers y restricciones, permite garantizar la integridad de los datos y de obtener una DDBB relacional excelente.
La mayoría de intervenciones manuales en el DDBB, o las debidas a las reglas de negocio programadas sin mucho esfuerzo en la capa intermedia, dan lugar a incoherencias en la información.
También cabe destacar, que un ERP con una DDBB relacional excelente, no da mucho margen para cambiar de producto para el motor de la base de datos, básicamente por falta de estandarización en las funciones entre los distintos fabricantes.
¿OpenERP, dispone de módulos de localización basados en la fiscalidad de cada país ?
¿OpenERP, dispone de un modulo de conciliación bancaria automatizado?
¿OpenERP permite arrancar a un mismo usuario, dentro de una única sesión varios procesos simultáneos?
Hola Josep,
El primer punto es cuestionable, si todo el código de base de datos estuviera diseñado por un administrador de base de datos posiblemente sería como tu dices, pero el caso es que el código de base de datos de Openbravo está escrito por desarrolladores para suplir carencias en la capa de negocio. Al final la base de datos tiene código que no está todo lo optimizado que debería y termina siendo lenta, muy lenta y ineficiente. Con sólo decirte que hay triggers que se ejecutan en cascada (trigger que hace un insert/update/delete que dispara otro trigger que a su vez dispara otro…) y provoca que en ciertas ventanas al guardar un registro se tarde decenas de segundos cuando debería ejecutarse en décimas de segundos.
Nadie ha dicho que en OpenERP no haya integridad referencial, se sigue utilizando Postresql, cada tabla tiene su clave primaria pero en lugar de un varchar de 32 como en Openbravo se utiliza un entero que indexa mil veces mejor. Los campos one2many, many2one, etc se mapean como se espera por lo que la incoherencia de datos no existe.
Si tu tienes una base de datos limpia de código y utilizas sql estándar, debería ser muy sencillo migrar de SGBD. No es que yo quiera cambiar Postgresql, que es fantástico, pero por lo menos el cliente tiene la opción de hacerlo. De todas formas de momento el ORM de OpenERP sólo funciona con Postgresql.
Las preguntas que haces no les encuentro sentido, obviamente OpenERP hace esas tres cosas sinó no estaría tan desplegado por ejemplo en España.
En cualquier caso como ya sabéis lo que me llevó a dejar Openbravo no eran tanto sus carencias técnicas, que no son tantas, de hecho yo lo considero un buen producto, sinó las tácticas comerciales y cambios de licencia que han ido aplicando.
Un saludo.
Hola Cheli,
Antetdos te agradezco tu interés por mis comentarios.
Estoy de acuerdo de que haya integridad referencial en OpenERP, pero esto no garantiza que la información contenida en la base de datos sea coherente. Existen como muy bien dices unas reglas de negocio que pueden afectar a esta coherencia, y normalmente cuando se realizan insert/updates, etc.. de forma manual, (cosa habitual en la mayoría de los programarios), producen incoherencias en la información.
El hecho de que el motor de la base de datos se transforme en ineficiente, normalmente se debe a la mala planificación de los recursos que precisa, ello conlleva a estas situaciones de falta de rendimiento. Para mí, no es nada más que la falta de formación y especialización de los técnicos, en estas instalaciones.
Todos sabemos que de Postgresql, surgió una base de datos comencial muy apreciada y utilizada.
Lo que te llevó a dejar Openbravo: esas tácticas comerciales y cambios de licencia que han ido aplicando y que todos hemos vivído. Piensa que en cualquier momento OpenERP acabará de la misma forma, de lo contrario que diferencia habría entre un OpenERP “libre, abierto, y sin posibilidad de poderle aplicar actualizaciones”, porque cada compañía ha programado su propio “castillo de cartas”, con un programario por ejemplo implantado en SQLServer y programado con VB.net. Todos ellos inHouse,,,
Mirate que ha ocurrido con el OpenOffice i el Libre Office….
Me permito una pregunta más:
¿OpenERP podrá ser actualizado con facilidad, una vez cada compañía hay preparado su propio Castillo de Cartas?
Saludos,
Josep
Hola Josep,
Antes de nada me voy a tomar la libertad de hacer un comentario para la gente que no es valenciano parlante, cuando Josep dice programario se refiere a software.
Cuando atacas directamente a la base de datos en OpenERP tienes que solventar a mano las reglas de negocio y flujos de trabajo asociados. Por ejemplo, si insertas una línea de factura no te va a calcular sus impuestos, vas a tener que ser tú el que inserte la cabecera de factura, las líneas, las líneas de impuestos, etc ya calculadas.
En cuanto a la actualización, lo cierto es que no es una tarea fácil pero no lo es en ningún ERP. En OpenERP hay herramientas para hacerlo que dan más o menos buenos resultados, también tienes un soporte oficial que consiste en enviar tu base de datos y ellos te la migran, luego tienes diversas iteraciones para depurar los posibles problemas. Mi opinión es que un ERP debería ser una herramienta de largo recorrido, eso significa que cuando alcanzas el punto de estabilidad suficiente para tu proyecto lo suyo es no actualizar la versión mayor hasta que termine el soporte de la misma. Este ciclo de vida debería ser almenos de 5 años, pero en muchos ERP no se cumple. Este apartado en OpenERP es mejorable, las actualizaciones deberían ser más sencillas y los ciclos de vida deberían ser más claros, a veces no sabes qué versión es LTS y cual no y cuanto tiempo vas a tener soporte. De esto ya hablé en su día cuando implantaba Openbravo y me planteaba los problemas de no tener un ciclo de vida largo.
Ciclo de vida de soporte recomendable para productos empresariales.
Ciclo de vida de soporte recomendable para productos empresariales 2.
Un saludo.
Buenas Tardes, estoy interesado en realizar el curso de desarrollo de OpenERP 7. Que pasos debo seguir para realizarlo?